
Before you can start forcing your pages into Google’s search results, it helps to understand how they get there in the first place. You need to get inside Google's head, so to speak. The whole system really boils down to three key actions: crawling, indexing, and serving.
Think of it like a massive, never-ending library project. First, Google has to find your book (your webpage), then read it to see what it's about, and finally, put it on the right shelf so people can find it when they search.

At its core, Google's mission is to organize all the information on the internet. To pull this off, it relies on a fleet of automated programs—often called spiders or bots, but officially known as Googlebot—that constantly roam the web. These bots jump from link to link, discovering new content and checking up on pages they've seen before, adding everything they find to Google's enormous digital library, the search index.
The scale here is almost impossible to comprehend. Google is constantly sifting through hundreds of billions of web pages to maintain an index that's over 100 million gigabytes in size. This is the engine that powers the nearly 9.5 million search queries people make every single minute.
Getting indexed isn't just a switch you flip; it's a process with several steps. It all kicks off with discovery. Googlebot finds your URLs, most often by following a link from a site it has already indexed or by processing an XML sitemap that you’ve submitted.
Once a URL is found, Googlebot "crawls" the page, downloading its text, images, and other files. And here’s where a huge shift in Google's process becomes critical: mobile-first indexing. This means Google now predominantly uses the mobile version of your site for both indexing and ranking. If your site doesn't work well on a phone, you're already starting at a major disadvantage.
After crawling, Google renders the page to see it just like a user would. It analyzes the content, layout, and structure to figure out what the page is all about. This is the "indexing" part—the moment Google decides if your page is good enough to be stored in its massive database.
Key Takeaway: A page can be crawled but not indexed. Google is always making a quality judgment. If it sees a page as low-value, a duplicate of something else, or just plain unhelpful, it might decide to leave it out of the index entirely.
Not every page gets an invitation to the party. Google has a finite amount of resources to spend on any given website, a concept known as the crawl budget. This budget is determined by things like your site's authority, technical health, and overall size.
Several common issues can stop a page from getting indexed:
Understanding this process is the first step to figuring out why your content isn't showing up. Before you can fix the problem, you have to know where it's coming from. For some hands-on troubleshooting, check out our guide on how to check if your website is indexed by Google.
Before you can get fancy with indexing strategies, you have to nail the fundamentals. This all starts by opening a direct line of communication with Google. And no, this isn't some weird SEO hack; it's a free, incredibly powerful tool that every single site owner should be using from day one.
Think of Google Search Console (GSC) as your website's command center for everything related to Google Search. It’s where you’ll monitor performance, ask Google to index your content, and get alerts when it runs into problems trying to crawl your site. If you do nothing else, do this.
The first, most critical step is verifying site ownership. This is simply you proving to Google that you're the legitimate owner of the website. Once you're verified, you unlock all the private data and tools inside GSC, which are absolutely essential for what comes next. Without it, you’re basically flying blind.
If you’re just starting out, getting the technical details right from the beginning makes a huge difference in how easily Google can find and index your pages. For a great walkthrough on this, check out this guide on Building a Website From Scratch.
Here’s a look at the Google Search Console homepage—this is where your indexing journey really begins.
This dashboard is your window into how Google sees your site. Get familiar with it.
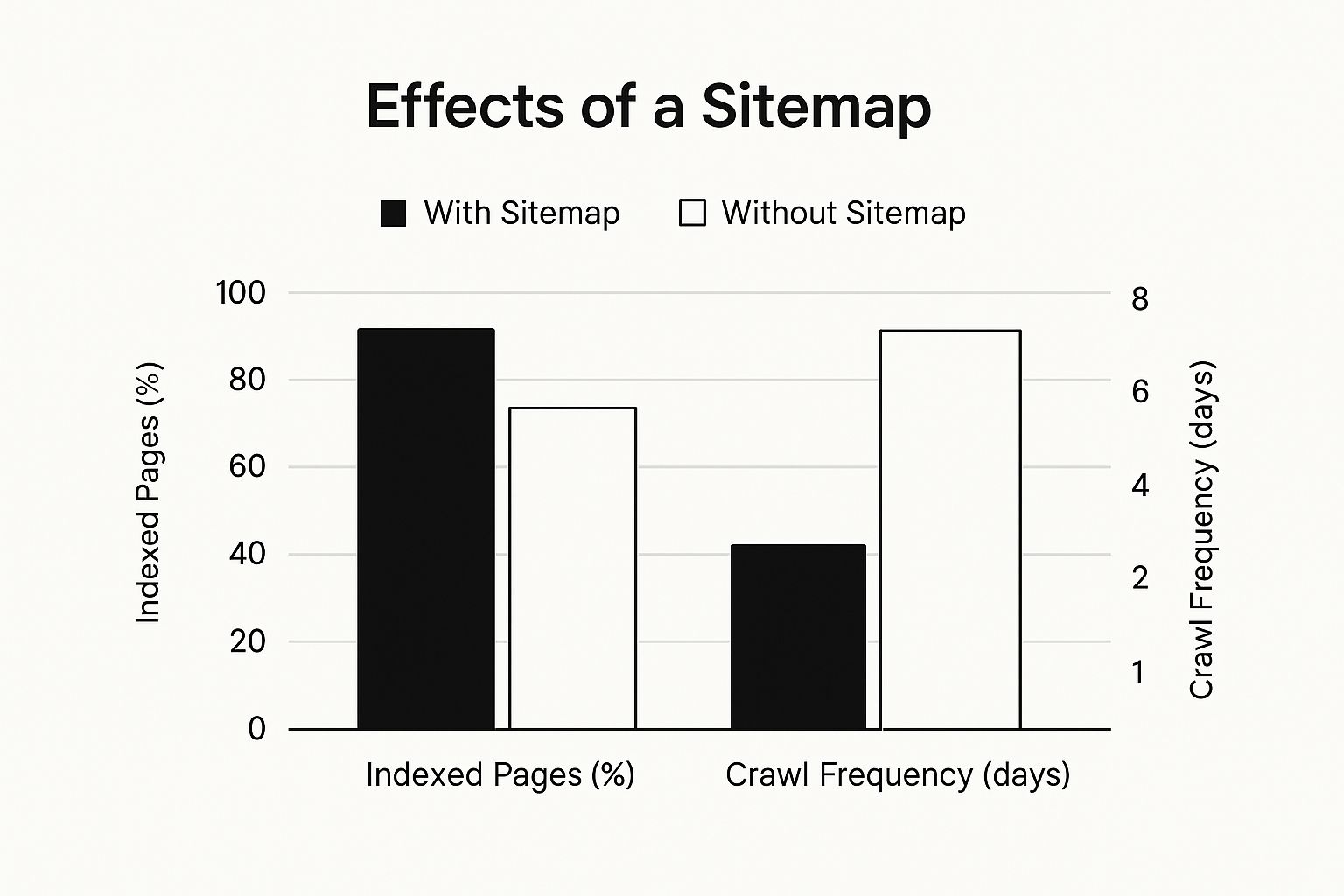
Once you’re set up in GSC, your next mission is to hand Google a map of your website. This is your XML sitemap. It’s a simple file that lists all the important URLs you want Google to know about. It’s like saying, "Hey Google, forget wandering around—here are my most important pages, please come check them out."
This is a step people surprisingly miss. Without a sitemap, you’re making Googlebot do all the heavy lifting by discovering your pages one link at a time. That’s slow and inefficient. A clean sitemap makes the whole process faster and more direct.
Most modern content management systems (like WordPress or Shopify) will generate a sitemap for you automatically. All you have to do is find its URL (it’s usually yourdomain.com/sitemap.xml) and paste it into the "Sitemaps" report in Google Search Console. It’s a two-minute job with a massive payoff.
A sitemap isn't something you can just set and forget. For it to be truly useful, it has to be accurate. A messy, outdated sitemap can actually do more harm than good by sending Googlebot on wild goose chases to broken links or unimportant pages.
To make sure your sitemap is an asset, not a liability, follow these best practices:
By getting set up in Google Search Console and submitting a clean, current sitemap, you’re building the foundation that all your other indexing efforts will depend on. This groundwork is the first and most important step toward getting your site seen by Google.

While a sitemap is your best friend for showing Google the big picture, sometimes you need to shine a spotlight on a single, high-priority page. This is where manual indexing requests become your most direct tool for getting Google’s attention right now.
Think of it this way: a sitemap is like handing over the blueprints for an entire neighborhood. A manual request is like picking up the phone and telling the city planner, "Hey, we just finished the new hospital—you need to come see this immediately."
This direct, page-by-page approach is perfect for time-sensitive updates. I find myself using it right after:
In these situations, waiting for a routine crawl could mean losing out on traffic and momentum when it matters most. A manual request essentially pushes your URL to the front of the line.
The main tool for this job is inside Google Search Console, and it's called the URL Inspection Tool. The process is wonderfully straightforward. Just copy the full URL of the page you want indexed, paste it into the search bar at the very top of your GSC dashboard, and press Enter.
Google will then fetch the status of that specific URL from its index. You'll typically get one of two results.
'URL is not on Google': This is exactly what you want to see for brand-new content. It’s a clean slate. Your next move is to click the "REQUEST INDEXING" button. This action adds your page to a priority crawl queue.
Once you've made the request, be patient. As Google themselves will tell you, mashing the button over and over won't speed things up. Trust the process and give it a few days. If you want to dive deeper into the best practices here, check out our guide on how to request Google to crawl your site.
But what if the tool says 'URL is on Google'? That’s great news! It confirms your page is already indexed and eligible to show up in search results. The report will even give you extra details, like how Google found the page, when it was last crawled, and if it’s mobile-friendly.
This status is especially useful after you've updated an existing page. Once you publish your changes, you can come back to the URL Inspection Tool and click "REQUEST INDEXING" again. This signals to Google that the content has been refreshed and is ready for a re-crawl. It's the best way to ensure the latest, most accurate version of your page is what appears in the SERPs.
When you've done everything by the book, it's incredibly frustrating to find your pages still stuck in indexing limbo. I've been there. You publish a great new piece of content, submit it, and then... crickets. It’s a common reality in SEO, but once you learn to diagnose the usual suspects, you can start clearing those roadblocks.
Your first port of call should always be Google Search Console. It’s the closest thing we have to a direct line to Google.
The most notorious—and confusing—status you’ll run into is ‘Crawled - currently not indexed’. This message drives SEOs crazy because it confirms Googlebot successfully visited your page. So, what's the problem? Google saw your page but decided not to add it to its index. This isn't a technical bug on your end; it's a quality judgment call from Google.
When you see this status, Google is essentially telling you, "I've seen this page, but I don't think it's valuable enough to show users right now." It's a soft rejection, and it usually boils down to a few core reasons:
This issue has become a lot more common. We saw a major spike in mid-2025 when Google's indexing rates seemed to drop off a cliff, pushing a huge number of otherwise good pages into the 'crawled - currently not indexed' bucket. This suggests Google is raising its quality bar, making it tougher than ever to get content indexed.
Beyond pure quality issues, a handful of technical gremlins can stop indexing in its tracks. The good news is these are often much easier to fix because they're usually caused by a specific, identifiable misconfiguration.
A shockingly common culprit is an accidental 'noindex' tag. This is just a tiny snippet of code in your page’s HTML (<meta name="robots" content="noindex">) that gives search engines a direct command: "Do not index this page." It's incredibly easy to add by mistake, especially if you're using certain WordPress plugins or staging site settings that you forgot to switch off.
Server-side problems can also slam the door on Googlebot. If Google tries to crawl your site and gets hit with a server error (like a 5xx status code), it's going to back off and try again later. If this happens consistently, Google will see your site as unreliable and may stop crawling it as frequently, which torpedoes your chances of getting new pages indexed.
Pro Tip: Make a habit of checking the 'Pages' report in Google Search Console. It neatly organizes all your known URLs into 'Indexed' and 'Not Indexed' lists. This gives you a clear, actionable starting point for figuring out which pages are having trouble and why.
If your site leans heavily on JavaScript for content, you have to ensure Google can render it correctly. If Googlebot can't see the content because of a script error, it's effectively looking at a blank page. Getting to the bottom of this often involves fixing JavaScript errors that prevent proper rendering.
Digging into why Google is not indexing your site almost always leads you back to one of these common—but thankfully fixable—issues.

Manually requesting indexing for a page or two is fine for one-off updates, but it just doesn't scale. If you're running a busy blog, a news site, or a large e-commerce store, trying to manually submit every new or updated page is a surefire way to fall behind. This is where automation flips the script, shifting you from playing defense to offense.
Automated systems can plug directly into Google's own tools, like the Indexing API, to send real-time pings whenever your site changes. The moment you hit "publish" on a new article or tweak an old one, these systems can notify Google instantly. This strategy transforms indexing from a reactive chore into a proactive, hands-off workflow.
The results can be a total game-changer, often leading to near-instant indexing. This gives you a clear advantage, especially when you're dealing with time-sensitive content where every minute of visibility counts.
Moving to an automated indexing strategy offers more than just saving time; it delivers a measurable competitive edge. When your content gets indexed faster, you capture traffic from breaking news or trending topics before competitors even get their pages crawled.
This is especially critical in today's search environment, where visibility is anything but guaranteed. It's a shocking statistic, but recent data shows that a staggering 61.94% of webpages remain completely unindexed by Google. Even for the pages that do get indexed, 93.2% appear within six months, which really drives home the need for fast and effective submission methods to make sure your content makes the cut.
By automating, you're not just speeding up a single task. You're building a more resilient and efficient system for managing your site's presence on Google. It’s about ensuring your best content gets seen immediately, not weeks or months later.
Third-party tools like IndexPilot are built specifically for this. They handle all the technical heavy lifting, connecting to the APIs and giving you a simple dashboard to monitor your indexing status in real-time. It effectively automates that crucial conversation between your website and Google.
While having a sitemap is essential for broad discovery, relying on automation ensures your most important updates are pushed directly. If you need a refresher on that, check out our guide on submitting a sitemap to Google.
To stay ahead of the curve, especially with the rise of AI in search results, it pays to use advanced tools. Exploring resources like this article on the best generative search optimization tools can give you a significant advantage, ensuring your content is positioned for how search engines will discover and rank content tomorrow.
Even when you follow all the best practices, you're going to have questions. Let's be honest, the world of Google indexing can feel like a bit of a black box. But once you get the answers to a few common queries, you’ll find most of the confusion clears up pretty fast.
Let's demystify some of the most frequent sticking points I see people run into.
This is the million-dollar question, and the only honest answer is: it depends.
For a brand-new website with zero authority, you could be waiting several weeks or even longer. On the other hand, for a well-established site that publishes high-quality content all the time, new pages might get indexed in just a matter of hours or days. It's a huge range.
Several things tip the scales:
There's no magic "index now" button that works every time, but submitting your sitemap via Google Search Console and manually requesting indexing for your most important pages is your best shot at speeding things up. Especially if your site is new, a little patience goes a long way.
It’s incredibly common to hear people use these terms interchangeably, but they are two totally separate stages of the process. I like to think of it like a librarian managing a new shipment of books.
Crawling is the discovery phase. This is when Googlebot follows links to find your webpage, like the librarian just finding a book in a shipping container.
Indexing is the analysis and storage phase. Here, Google analyzes the page's content and decides if it’s good enough to be added to its massive database—just like the librarian reads the book and decides where to put it on the shelves.
A page can be crawled but not indexed. This happens all the time. Google might find your content but decide it's low-quality, a duplicate of another page, or see a 'noindex' tag telling it to stay away. The real goal is getting your important pages both crawled and indexed.
Nope. You absolutely cannot pay Google for faster or preferential treatment in its organic search index. Let me be clear: Google's organic indexing process is completely walled off from its advertising platforms like Google Ads.
Sure, running a Google Ads campaign can get your pages to show up in the paid search results almost instantly. But this has zero impact on your organic indexing speed or your actual search rankings.
The only way to get indexed faster organically is through solid, consistent SEO work: creating content people actually want to read, building a technically sound website, and using the free tools Google gives you.
If you feel like you're constantly hitting a wall and your content just isn't getting seen, it might be time to look a little deeper. You can learn more about diagnosing some of the most common website indexing issues to figure out what's holding you back.
Tired of manually checking your indexing status? IndexPilot automates the entire process. Our platform monitors your sitemap in real-time, automatically notifying Google the moment you publish or update content. Stop waiting and start indexing. Try our 14-day free trial and see the difference.