
Let's get straight to the point: if you want to increase your Google crawl rate, the single biggest lever you can pull is your server's performance. It’s not just about speed—it's about stability, reliability, and how efficiently you can hand over content to Googlebot. A fast, dependable server is a direct invitation for Googlebot to crawl more pages every time it visits, maximizing your crawl budget.

I like to think of Googlebot as a guest with a very tight schedule. When it stops by your site, it has a limited window of time—its "crawl budget"—to look around. If your server takes ages to respond, it's like a host who takes five minutes just to answer the doorbell. By the time the door finally swings open, the guest has less time to actually explore.
That's the relationship between server performance and crawl rate in a nutshell. A sluggish server forces Googlebot to wait around, wasting its allocated time. Instead of zipping through ten or twenty pages, it might only get through two or three before its visit is over.
For years, the common wisdom was that crawl budget was a problem reserved for massive websites with millions of pages. That thinking is outdated. We now have insights straight from Google’s own team confirming the real bottleneck isn't the number of URLs you have, but the speed at which your server can deliver them.
According to a recent analysis from Google's Search Relations team, crawl budget is now primarily limited by "host load"—how fast and efficiently your server can serve pages. Websites that respond quickly allow Googlebot to crawl more pages in the same amount of time. This means slow servers or clunky database queries are actively throttling your crawl rate, regardless of whether you have 100 pages or a million. You can dig deeper into how speed now matters more than site size on StanVentures.com.
This makes perfect sense when you see it in the wild. I've seen small e-commerce stores with slow, complex database lookups for every product page burn through their crawl budget faster than a massive but highly optimized publisher.
Key Takeaway: Your server’s ability to quickly deliver content is the most critical factor influencing your crawl budget. A fast server is a direct invitation for Googlebot to crawl more of your site, more often.
Server-side issues are often the invisible culprits holding back your SEO. They don't show up as obvious on-page errors, but their impact is huge. Before you dive into optimizing content or links, you have to look at what's happening behind the scenes.
To help you diagnose potential issues, here's a breakdown of common server metrics and how they directly affect Google's ability to crawl your site.
This table breaks down the key performance indicators for your server and explains how each one directly affects Googlebot's ability to crawl your site efficiently.
Think of these metrics as your server's vital signs. If any of them are unhealthy, your site's ability to get crawled and indexed will suffer. The goal is to make it as easy and fast as possible for Googlebot to do its job.
Here are a few of the most common server-side bottlenecks I see that absolutely kill crawl rate:
Once you’ve tuned up your server for performance, it's time to work on what we call "crawl demand." It’s a simple concept: you need to give Googlebot a reason to visit your site frequently.
Think of it this way: a fast server opens the door, but fresh, valuable content is the invitation that makes Google want to walk through it again and again.
The whole game is about signaling to Google that your site is a dynamic, active, and genuinely useful resource. This isn't about trying to trick the algorithm. It's about getting your content strategy in sync with what Google values most: freshness and quality.
Before you can plant new seeds, you have to weed the garden. Over the years, most websites accumulate a ton of low-value, outdated, or thin pages. This digital clutter is like dead weight, wasting your precious crawl budget every time Googlebot stops by.
That’s why a content audit is your first and most critical move. Your goal here is to find the pages that get little to no traffic, have terrible engagement metrics, or are just plain outdated. These are your prime candidates for pruning.
By cleaning house, you force Google to stop wasting time on the junk and focus its attention on the pages that actually matter. It’s one of the most effective ways to make every crawl count.
By focusing Googlebot’s attention on your most important content, you improve crawl efficiency. Every URL that is noindexed or removed is one less page wasting your limited crawl budget.
This whole process ensures that when Googlebot visits, its time is spent productively. Instead of getting lost on some forgotten blog post from 2012, it can dedicate its resources to your brand-new cornerstone content and freshly updated pages.
Google’s crawlers are smart. Their behavior is heavily influenced by a site's content quality, its popularity, and how often it's updated. This trifecta is what Google refers to as crawl demand. Pages that are popular or change often get crawled more frequently to keep them fresh in the index. You can get the full rundown on this from Google's official documentation on managing your crawl budget.
Finding a consistent rhythm for content updates tells Google that your site is a reliable source of new information. For some sites, this might mean publishing one deeply researched article every week. For a news-focused site, it could be several times a day. The schedule itself matters less than the consistency.
This is also where smart search engine indexing management comes into play. It's not just about what you publish, but also about what you tell Google to ignore. Use the noindex tag on pages that have no business being in search results (like thank-you pages or internal search result pages). And always use canonical tags to sort out any duplicate content issues.
Think of it as giving Googlebot a clear map. By providing this kind of strategic guidance, you prevent it from getting sidetracked by low-value URLs and help it focus on the content you actually want to rank.
If your server performance opens the door for Googlebot, your sitemap and internal links are the well-lit hallways that guide it through your site. Just submitting a single, massive XML sitemap is table stakes. To really get Google crawling more often, you have to architect a clear path for the bots to follow.
Think of your sitemap as a GPS you hand-deliver to Google. A messy, outdated map only causes confusion. But a precise, dynamic one? That ensures every important destination gets found. I see it all the time: people treat the sitemap as a "set it and forget it" file, which is a huge missed opportunity. You have to keep it fresh to make it a powerful tool.
The <lastmod> tag is your secret weapon here. Every time you update a page, your system should automatically update this tag. It sends a direct signal to Google that says, "Hey, something new and important just happened here—it’s worth a look." This simple action encourages crawlers to prioritize your updated content over pages that haven't changed in months.
For bigger sites, a single sitemap can get bloated and incredibly slow for Google to process.
A much better approach is to break it down into smaller, more focused files. You could have separate sitemaps for your blog posts, your product pages, and your main service pages. This makes it far easier and faster for Google to process changes within specific sections of your site.
For a deeper dive into structuring these files properly, our guide on sitemap optimization lays out detailed strategies you can use right away.
While sitemaps are essential, internal links are the unsung heroes of crawlability. They’re the connective tissue of your website, guiding both users and search engine bots from one page to the next. When done right, a logical internal linking structure creates a clear hierarchy, signaling which pages are the most important.
This is a great way to visualize how a strong site structure guides crawlers to your key content.
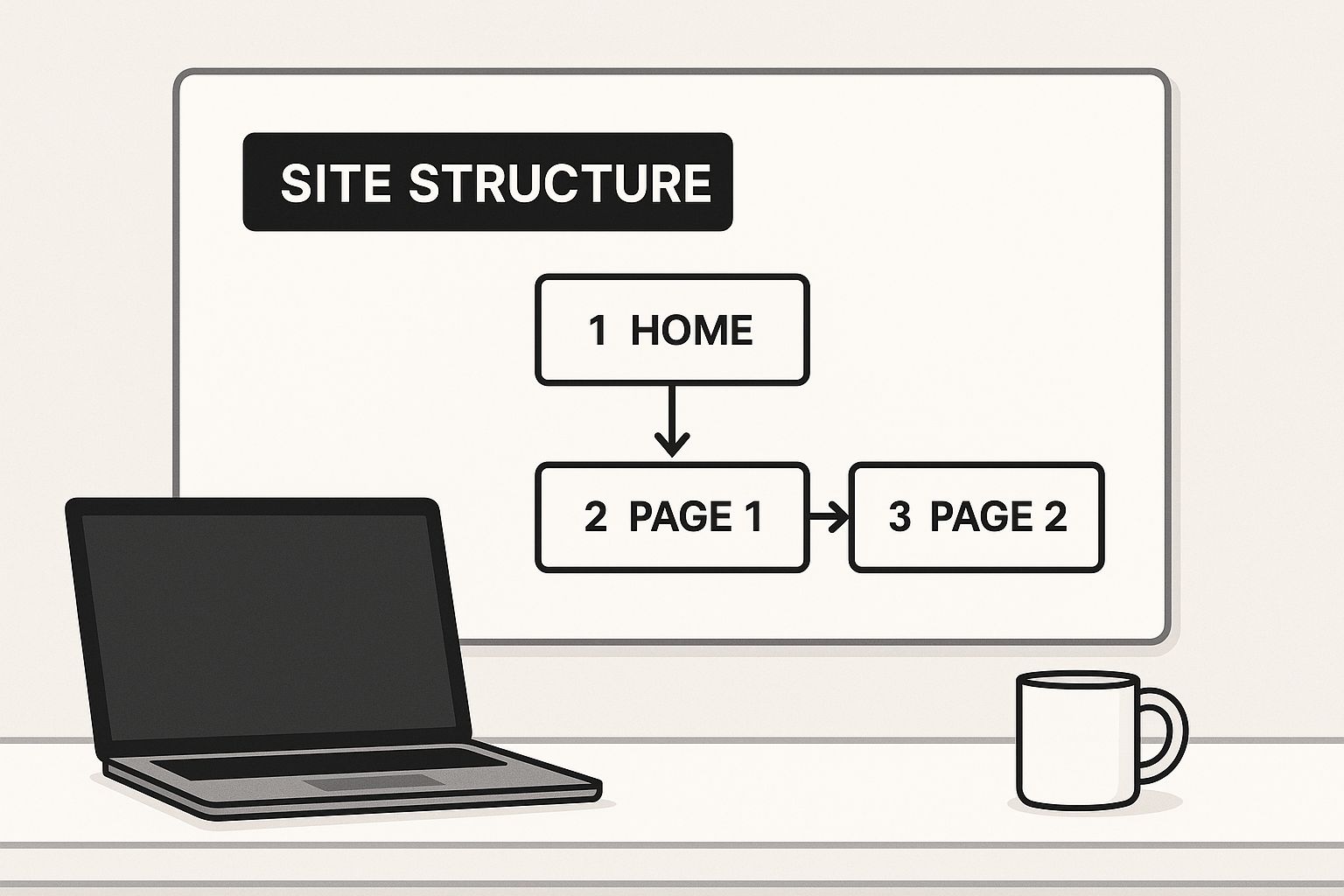
The diagram shows how authority—and crawl priority—flows down from the homepage to important category and sub-pages. This makes the entire site much easier for bots to navigate and understand.
A strong structure links from high-authority pages (like your homepage) to your most critical content, effectively funneling "link equity" and crawl priority where it matters most. A weak structure, on the other hand, leaves important pages isolated. These orphaned pages have few or no internal links pointing to them, making them nearly invisible to Googlebot.
Fixing this is straightforward. You just need to regularly audit your site for orphaned content. A simple framework looks like this:
This process creates a robust web of connections that makes your entire site more crawlable and tells Google exactly what content you value most.
Sometimes the biggest thing holding back your Google crawl rate is a roadblock you accidentally put there yourself. It’s a frustrating but common scenario—hidden technical issues can quietly sabotage all your other efforts, making a perfectly good site nearly invisible to search engines. Finding and fixing these traps is one of the most important steps you can take to get Googlebot working for you, not against you.
A single bad line in your robots.txt file is a classic example. A seemingly harmless Disallow directive can easily block Google from entire sections of your site, including the CSS or JavaScript files it needs to actually see your pages correctly. When Google can't render your pages, crawling and indexing both take a serious hit.
More often than not, the really subtle problems come from security settings that are just a little too aggressive. Many firewalls, security plugins, and even Content Delivery Networks (CDNs) are designed to spot and block suspicious bot activity. The catch? They can sometimes mistake the perfectly legitimate Googlebot for a threat, slowing it down or blocking its access entirely.
This kind of misidentification can absolutely crush your crawl rate. In one recent, high-profile case, a few major CDNs were slow to update their firewall rules after Google changed its crawler IP ranges. The result was a disaster for their customers—websites using these services saw a massive drop in crawl activity as Googlebot requests were either rate-limited or flat-out blocked.
The more proactive CDN providers avoided this mess, but it’s a stark reminder of why you need to keep your security configurations up to date. You can dig into the specifics of this case study on Google crawl disruptions over at Analyzify.
Pro Tip: Don't just "set and forget" your security rules. Make it a habit to audit your firewall, CDN, and security plugin logs. You're looking for patterns of blocked requests coming from known Googlebot user agents or IP ranges. This simple check can help you catch a problem before it tanks your traffic.
To make sure your site is always open for business when Google comes knocking, you need a routine check-up process. Think of it as a regular health screening for your site’s technical accessibility. Staying on top of these areas will help you prevent those sudden, scary drops in crawl activity.
Here’s a practical checklist I run through:
robots.txt for Errors: Pop open Google Search Console’s robots.txt Tester and confirm you aren’t accidentally blocking important resources. Be on the lookout for overly broad Disallow rules that might be catching more than you intended.By staying on top of these technical details, you’re removing the invisible walls that could be holding your site back. Once you find and fix an issue, it’s a smart move to let Google know right away. You can check out our guide on how to request Google to crawl your site to get your updated pages re-evaluated as quickly as possible.

Why sit around waiting for Google to eventually find your new content? You can—and should—tell them about it the second it goes live. That's the simple but powerful idea behind indexing APIs. It’s a complete shift in dynamics, moving from passively waiting to be discovered to actively announcing your content.
Think of it like having a direct line to the search engines, letting you skip the line and get your pages in front of the crawlers much faster.
This is a game-changer for any site with time-sensitive information. If you're running a news site, an e-commerce store with flash sales, or a job board, the value of your content decays quickly. An indexing API ensures search engines get notified instantly, slashing the delay between hitting "publish" and showing up in search results.
The biggest name in this space right now is the IndexNow protocol. It's an open-source project backed by major search engines like Bing and Yandex. When you publish or update a URL, you simply "ping" the IndexNow API. That one ping alerts all participating search engines at once, which is incredibly efficient.
So, where does Google fit in? While they aren't an official part of the IndexNow initiative, they've publicly confirmed they monitor these signals. In my experience, this means using IndexNow can absolutely give you a nudge to increase your Google crawl rate, even if it's an indirect one. It's a low-effort, high-reward tactic.
By sending a simple notification, you’re telling search engines: “Hey, this URL just changed and it’s ready for you.” This proactive signal encourages bots to visit your site outside their regular schedule, focusing their precious resources right where you need them.
If you’re looking to put this on autopilot, plenty of tools can handle it for you. Platforms like IndexPilot, for example, plug right into your sitemap. They automatically spot new or updated pages and ping the indexing APIs without you lifting a finger. You can learn more about this approach by checking out guides on instant indexing.
Getting started with indexing APIs is easier than it sounds. You have a few solid options, depending on your technical skills and your website's setup.
Here are the most common ways to do it:
By adopting one of these methods, you gain a powerful way to signal content freshness, giving you a serious competitive edge in getting your pages crawled and indexed faster.
Even when you've done everything right, a few practical questions always pop up. Let's dig into some of the most common ones I hear. Getting these answers straight will help you set realistic expectations and troubleshoot issues as they arise.
This is where patience really pays off. Tweaking your site's crawl rate isn't like flipping a switch; it's more like turning a massive ship. The changes aren't instantaneous. After you've beefed up your server, cleaned up your content, and sorted out technical glitches, Googlebot needs time to notice these improvements on its next few visits.
Generally, you might start to see shifts in your crawl stats within a few weeks, not a few days. The first sign is often a drop in the "time spent downloading a page" metric inside Google Search Console. Soon after, you should see a gradual, steady increase in the number of pages crawled per day.
This is the classic "it depends" scenario. A "good" crawl rate is completely relative to your website. A news site pushing out 50 articles a day will have—and need—a vastly different crawl rate than a small business that updates its blog once a week. There’s no magic number to aim for.
Instead, look for signs of a healthy crawl rate:
The goal isn’t just a high crawl rate; it’s an efficient crawl rate. You want Googlebot spending its limited budget on your most valuable pages, not getting lost in a maze of low-quality content or hitting server errors.
Nope. Back in the day, Google Search Console actually had a feature that let webmasters suggest a preferred crawl rate. But that setting has been gone for a long, long time. Why? Because Google's algorithms are now far more sophisticated at figuring out the optimal rate on their own, based on signals like your server health and how much new content you have (what they call "crawl demand").
Trying to force a higher crawl rate on a server that isn't ready would be like demanding a delivery driver make twice as many stops without giving them a faster truck or more gas—it just leads to breakdowns. Your best bet for influencing the crawl rate is to make the improvements we've discussed.
If you’re convinced there's a major problem, your only "manual" option is to report it to Google, but there's no simple lever you can pull to crank things up.
A handful of 404 (Not Found) errors is perfectly normal for any website and will not negatively affect your crawl rate or your rankings. Google knows that pages get deleted and URLs sometimes change. It's just part of a site's lifecycle.
The real trouble starts when there's a sudden, massive spike in 404s. This can signal to Googlebot that something is fundamentally broken with your site’s structure, prompting it to slow down its crawl to avoid wasting resources on dead ends.
The key is to focus on fixing broken internal links that point to these 404 pages. And if you need a quick refresher on the basics, our guide on how to submit a website to search engines walks through the foundational steps that ensure Google can find your site in the first place.